JAXAgents: a package for efficient (Multi-Agent) Reinforcement Learning
JAXAgents is a high-performance (Multi-Agent) Reinforcement Learning library built on JAX, designed for rapid experimentation, scalable training of RL agents and fast hyperparameter tuning. It supports a variety of algorithms and environments, making it suitable for both research and practical applications.
Also available on PyPI
🛠️ Features
- RL: Implementations of popular RL algorithms, including:
- Q-learning:
- Deep Q Networks (DQN)
- Double Deep Q Networks (DDQN)
- Categorical DQN (C51)
- Quantile Regression DQN (QRDQN)
- Policy Gradient:
- REINFORCE
- Proximal Policy Optimization (PPO) with Generalized Advantage Estimation (GAE)
- Multi-Agent RL:
- Independent PPO (IPPO)
- Q-learning:
-
High Performance: Leveraging JAX’s capabilities for just-in-time compilation and automatic differentiation, enabling efficient computation on CPUs and GPUs.
- Modular Design: Structured for easy extension and customization, facilitating experimentation with new algorithms and environments.
🏁 Getting Started
Here’s a simple example to train a PPO agent:
import jaxagents
# Initialize environment and agent
env = jaxagents.environments.make('CartPole-v1')
agent = jaxagents.agents.PPO(env)
# Train the agent
agent.train(num_episodes=1000)
For more detailed examples and usage, refer to the documentation.
🚀 Performance
JAXAgents enables extremely fast optimization. Below is an example of a PPO agent trained on CartPole-v1 — achieving near-optimal performance within approximately 100 episodes:
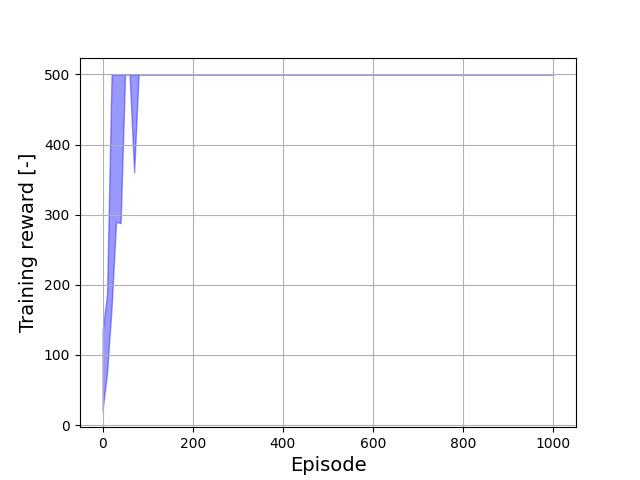
Minimum and maximum returns per training episode.
JAXAgents enables lightning-fast learning: PPO solves CartPole-v1 in approximately 100 episodes.
📖 Documentation
Comprehensive documentation is available at amavrits.github.io, covering:
- Installation and setup
- Detailed API references
- Tutorials and examples
- Advanced topics and customization